My roommate needed help with building a web scraper. As a result of various
constraints, we ended up using Heroku. There was, however, a database row limit
that we had to work around. It turned out to be a nice opportunity to play with
the new PostgreSQL 9.5 INSERT ... ON CONFLICT DO UPDATE, also known as UPSERT,
functionality. The goal of this article is to introduce UPSERT to you via a
practical example.
Introduction
My roommate, an aspiring programmer, recently asked me for advice on how to build a web scraper. The scraper should run on a machine that is constanly connected to the internet, because it should check at least every hour or so. Running the scraper on his laptop is not an option for my roommate, because he frequently takes it with him on the road. Neither is running it on a remote server, because he possesses none nor is he planning to spend money on one. We tried out Heroku; a free platform as a service provider that embraces all of these constraints.
Choosing the right storage
The Heroku Scheduler addon enabled us to run a script every 10 minutes (the highest available frequency) that scrapes the targeted website. With that requirement settled, we needed a way to compare the old state to the new state, so we could send ourselves an email as soon as the website changed. The simplest solution we could come up with involved saving the hashed HTML contents into a Heroku config variable. That solves the problem of notification, but will not allow us analyse the data later. For this reason, using a database made sense. PostgreSQL storage is cheap, free actually on Heroku, so we picked that one.
Heroku limitations
Normally, I would insert one row per scraping run with the scraped contents (or a foreign key to a unique piece of content) and a timestamp into the database. In this case, however, it was not a good idea because the free Heroku PostgreSQL database offering has certain limitations. You are allowed to have a maximum of 10.000 rows in the database. A scraper that scrapes every 10 minutes reaches the limit after 40 days of service. We needed a way to circumvent the limitation, since we were planning on scraping longer than that.
What if we scaled horizontally instead of vertically? Instead of adding rows, we
could grow columns and consequently circumvent the row limit. One row per unique
piece of scraped content with an ever expanding array of timestamps. PostgreSQL
arrays seem to be a good fit for this. One could implement this using two
queries. First, a SELECT establishes whether we have seen the content
before. Second, an INSERT or UPDATE respectively inserts a new piece of
content with the current time to the array or updates an existing row by
appending the current time. Or, you use the new INSERT … ON CONFLICT DO UPDATE
operation instead, like I will show you in this article.
Methods
In this article, I will only show you how to complete the task using UPSERT. If you would like to see how you could achieve similar behavior with PostgreSQL versions below 9.5, please check out this Stackoverflow answer.
The query
We built the plumbing of the scraper using Python; the source code is available on GitHub. The Python script executes the following query–the interesting part–every time it runs.
CREATE TABLE IF NOT EXISTS scraps (
id serial PRIMARY KEY,
hash bytea NOT NULL UNIQUE,
body text NOT NULL,
seen_at timestamptz[] NOT NULL
);
-- This extension yields the digest function that enables us to
-- hash the body and index it efficiently. Moreover, PostgreSQL
-- does not allow indexes on very large text columns. We expect to
-- store large HTML bodies so we definitely need the hashing.
CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Capture the script input (body) via a CTE (the WITH part) so we
-- can use it multiple times in the query. Once to save the body,
-- once to hash it.
WITH body AS (SELECT :body::text AS txt)
-- This is exactly the INSERT you would write without UPSERT.
INSERT INTO scraps (hash, body, seen_at)
SELECT digest(txt, 'sha1'), txt, ARRAY[:ts::timestamptz]
FROM body
-- Here it gets interesting; we utilize the UNIQUE index on hash
-- to yield a conflict if the body already exists. If that
-- happens, we append the new seen_at (via the special 'EXCLUDED'
-- table) to the seen_at array.
ON CONFLICT (hash) DO UPDATE
SET seen_at = scraps.seen_at || EXCLUDED.seen_at
-- The query returns a summary of the row so I can use it in my
-- blog post. This part will run, but the output is ignored, in
-- production.
RETURNING id, left(hash::text, 3) || '...' hash, body, seen_at;The test
We supply the query above to the script below via the $QUERY variable. First,
we initialize an empty database and run the query twice with the body variable
set to content and ts set to the SQL function now(). After that, we
simulate a change on the targeted website by running the query again after
setting content to changed. In production, the body variable contains an
HTML document. The output of the script is printed below it.
dropdb --if-exists scraper_test
createdb scraper_test
psql scraper_test --variable body="'content'" \
--variable ts='now()' \
<<EOF
$QUERY
$QUERY
EOF
echo \\nContent changed...\\n
psql scraper_test --variable body="'changed'" \
--variable ts='now()' \
<<EOF
$QUERY
EOFCREATE TABLE
CREATE EXTENSION
id | hash | body | seen_at
----+--------+---------+----------------------------------
1 | \x0... | content | {"2016-04-20 11:05:31.38508+02"}
(1 row)
INSERT 0 1
CREATE TABLE
CREATE EXTENSION
id | hash | body | seen_at
----+--------+---------+------------------------------------------------------------------
1 | \x0... | content | {"2016-04-20 11:05:31.38508+02","2016-04-20 11:05:31.386758+02"}
(1 row)
INSERT 0 1
Content changed...
CREATE TABLE
CREATE EXTENSION
id | hash | body | seen_at
----+--------+---------+-----------------------------------
3 | \x3... | changed | {"2016-04-20 11:05:31.397775+02"}
(1 row)
INSERT 0 1Results
The scraper has been running flawlessly in production for almost two weeks. Let’s see how many rows have been added during that time.
SELECT count(*) FROM scraps24After running every 10 minutes for almost two weeks, the scraper inserted just 24 records. Before we inspect the contents of the database, let’s make sure that we really are in compliance with the Heroku PostgreSQL maximum rows limitation:
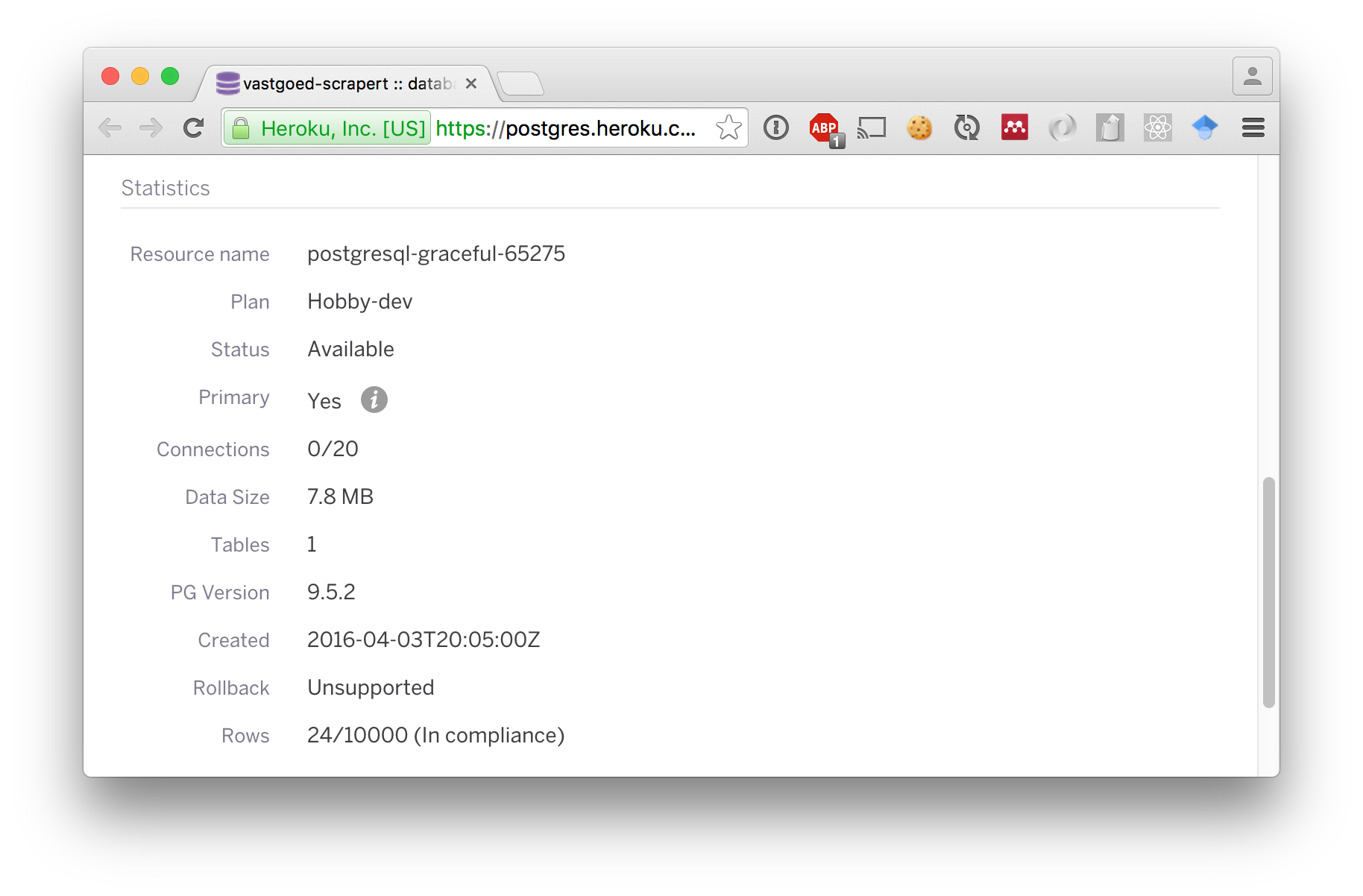
We have to unnest the seen_at array to obtain the total count of scraper
runs.
SELECT count(*) FROM (SELECT unnest(seen_at) FROM scraps) un2282Let’s break the 2282 rows down by date and aggregate the count of checks and changes of content that occured that day. Please check out the appendix for the exact query that I used.
day | checks | changes
------------+--------+---------
2016-04-04 | 87 | 0
2016-04-05 | 144 | 1
2016-04-06 | 144 | 0
2016-04-07 | 139 | 3
2016-04-08 | 144 | 4
2016-04-09 | 144 | 0
2016-04-10 | 144 | 0
2016-04-11 | 141 | 2
2016-04-12 | 144 | 4
2016-04-13 | 144 | 1
2016-04-14 | 138 | 3
2016-04-15 | 139 | 0
2016-04-16 | 144 | 0
2016-04-17 | 144 | 0
2016-04-18 | 143 | 4
2016-04-19 | 144 | 2
2016-04-20 | 55 | 0
Total: | 2282 | 24The sums of checks and changes match the unnested and total counts above, respectively. Note: the amount of checks differs between days probably because of the following:
Scheduler is a best-effort service. There is no guarantee that jobs will execute at their scheduled time, or at all. Scheduler has a known issue whereby scheduled processes are occasionally skipped.
Source: Known issues and alternatives; Heroku Scheduler documentation
Discussion
This scraping method only works when the website is static and the content changes slowly, compared to dynamic websites with different HTML output on each request. For example, some websites return a different XSRF token at every visit. In that case, every scraping run inserts a new row into the database, negating the savings of our UPSERT horizontal expansion.
Conclusion
The HTML output of our targeted website only changed when the content of interest changed, leading to our high checks vs. changes ratio. Using UPSERT for scraping turned out to be a good fit for this website because it enables us to scrape for some time ahead, while logging all of the captured data.
Acknowledgements
Thank you people that made Org mode and Babel. :-)
Appendix
The source code of this article is available online.
Breakdown query
WITH base AS (SELECT
date_trunc('day', seen_at)::date::text AS day,
count(*) checks,
count(DISTINCT body) - 1 changes
FROM (SELECT unnest(seen_at) seen_at, body FROM scraps) un
GROUP BY day)
SELECT * FROM base
UNION
SELECT 'Total:', sum(checks), sum(changes) FROM base
ORDER BY daySoftware used
PostgreSQL
psql postgres --tuples-only -c 'SELECT version()'PostgreSQL 9.5.2 on x86_64-apple-darwin15.4.0, compiled by Apple LLVM version 7.3.0 (clang-703.0.29), 64-bitpsql
psql --versionpsql (PostgreSQL) 9.5.2